A service for mining changes and interactions from revisioned writing platforms.
Introduction 
Introduction to the functionality of wikiwho.
Services
APIs and Data sets, ready to use
Or: Shortcut to the APIs
Technical Details
Description of the core algorithm, source code, papers
Tools and further use cases
Well, tools and further use cases
Introduction
- The core functionality of WikiWho: given a revisioned text document, it parses the complete set of all historical revisions (versions) in order to find out who wrote and/or removed and/or reinserted which exact text at token level at what revision. This means that for every token (~word), its individual add/removal/reintroduction history becomes available.
- Initial and currently sole use case: Wikipedia articles in different languages (Each edit on an article creates a new revision). Other systems planned.
- While it might sound as if you could achieve this with standard text diff approaches: it is not that trivial. And usually, this information is not readily available from revisioned writing systems. See Technical Details .
- Consequently, WikiWho is – as of writing – the only source of this information in real time for multiple Wikipedia language editions and which is scientifically evaluated for the English Wikipedia with at least 95% accuracy.
- On top of this fine-grained change data, there are many possible applications: One is to aid editors with improved change tracking in interfaces and seeing their editing impact. Another one is to focus on the longevity of and disputes about certain n-grams, an interesting linguistic question, especially in the large corpus of Wikipedia. Thirdly, it allows studying the minute change interaction of editors with each others content, allowing to infer social interaction networks from them – i.e., to investigate collaboration vs. conflict in online writing.
- We provide the core data as open APIs and datasets , as well as additional resources. Check them out below .
- WikiWho was first conceived as a dissertation project at Karlsruhe Institute of Technology by Fabian Flöck and collaborators and is now hosted, maintained and further developed at GESIS – Leibniz Institute for the Social Sciences, CSS department. The main goal is to provide (computational) social scientists easier access to the rich interaction and collaboration data “hidden” in the change logs of revisioned writing systems. It is thereby part of one of GESIS’ missions, namely to enable accessibility for digital behavioral trace data to scientific stakeholders studying social phenomena.
Services
APIs
We offer APIs (1 per language) for word provenance/changes of Wikipedia articles: You can get token-wise information from which revision what content originated (and thereby which editor originally authored the word) as well as all changes a token was ever subject to. An additional set of APIs delivers special HTML markup for interface applications, e.g., the browser extension WhoColor. To see how it works and what languages we offer, take a look at the API page.
Data sets
Periodically, we export our collected and processed data (that you can get over the APIs) and publish a cleaned up and documented dataset in an easy-to-consume format. Currently we offer the following data dumps, which we will expand in the future:
- TokTrack: A Complete Token Provenance and Change Tracking Dataset. (containing
every
instance of all tokens ever written in undeleted, non-redirect articles.)
Each token is annotated with: (i) the article revision it was originally created in, and
(ii) lists
with all the revisions in which the token was ever deleted and (potentially) re-added
and re-deleted from its article. An ICWSM’17
dataset paper explains what you can do with
that data, and shows some novel statistics about the English Wikipedia in that regard.
- English, until Nov. 2016 (>13 Billion tokens)
Technical Details
The original algorithm working behind the scenes is described in a WWW 2014 paper, along with an extensive evaluation resulting in 95% accuracy on fairly revision-rich articles. The current code version is available on GitHub.
In a nutshell, the approach divides each revision into hierarchically nested paragraph, sentence and token elements and tracks their appearance through the complete content graph it builds in this way over all revisions. It is implemented currently for Wikitext, but can run on any kind of text in principle (although tokenization rules might have to be adapted).
Toy example for how the token metadata is generated:
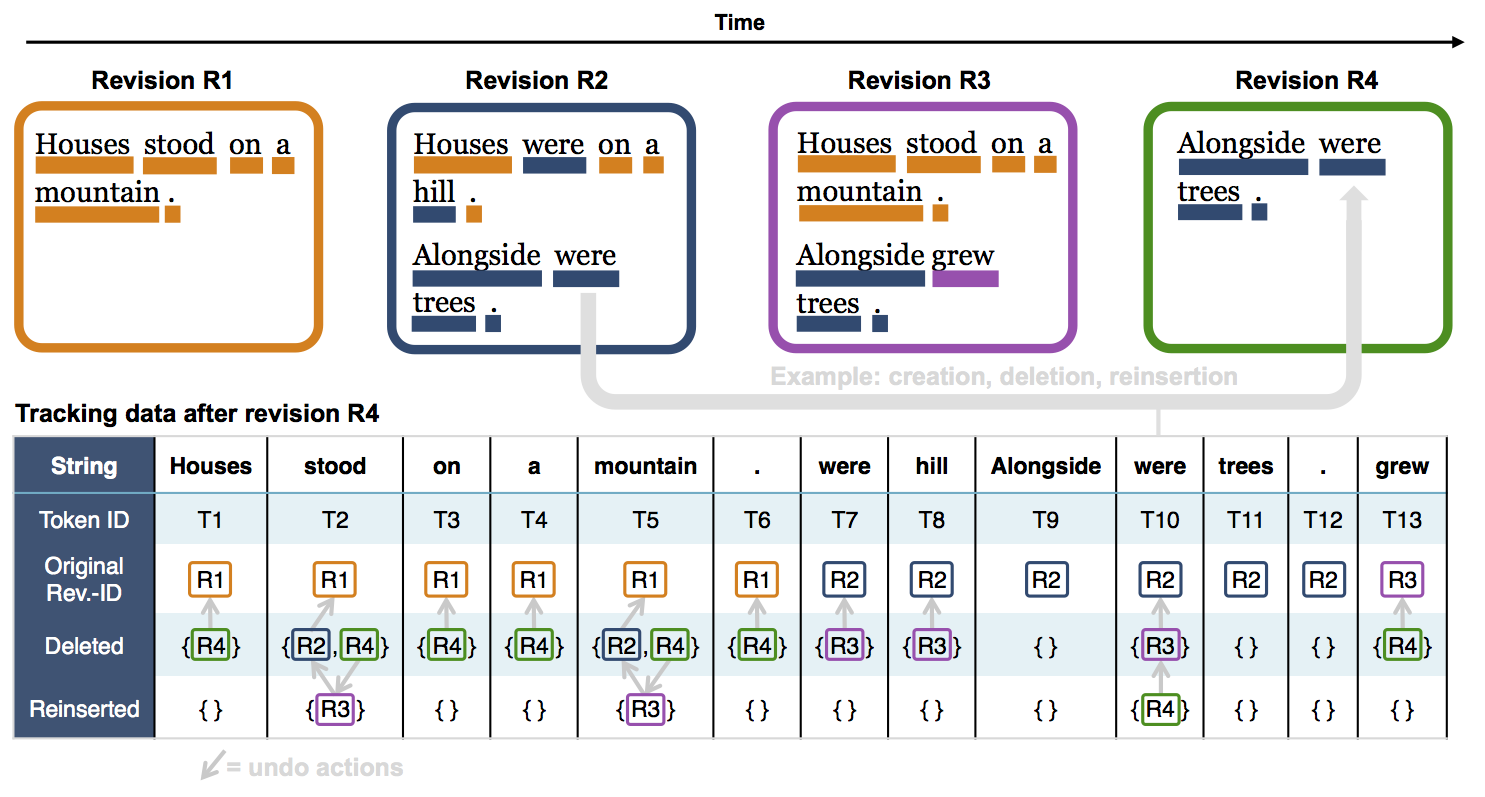
In this way, it becomes possible to track – for each single token – all original additions, deletes, reinserts and redeletes and in which revision they took place. Which in turn allows to infer the editor, timestamp, etc. of those revisions. Also, individual tokens retain a unique ID, making it possible to distinguish two tokens with identical strings in different text positions.
Tools and further use cases
From the generated provenance and change data further new forms of data can be mined and novel tools can be built.
We already provide the WhoColor userscript for the Tamper-/Greasemonkey browser extensions (download here, documentation here), using live data from the WhoColor API. Opening a Wikipedia article it creates a color-markup on the text, showing the original authors of the content, an author list ordered by percentages of the article written and additional provenance information. It also has the ability to show conflict regarding certain text parts and the adding/deleting history of a given word. The Wiki Edu Foundation currently uses the WhoColor API for a similar display of authorship in its dashboard for students learning to edit Wiki articles.
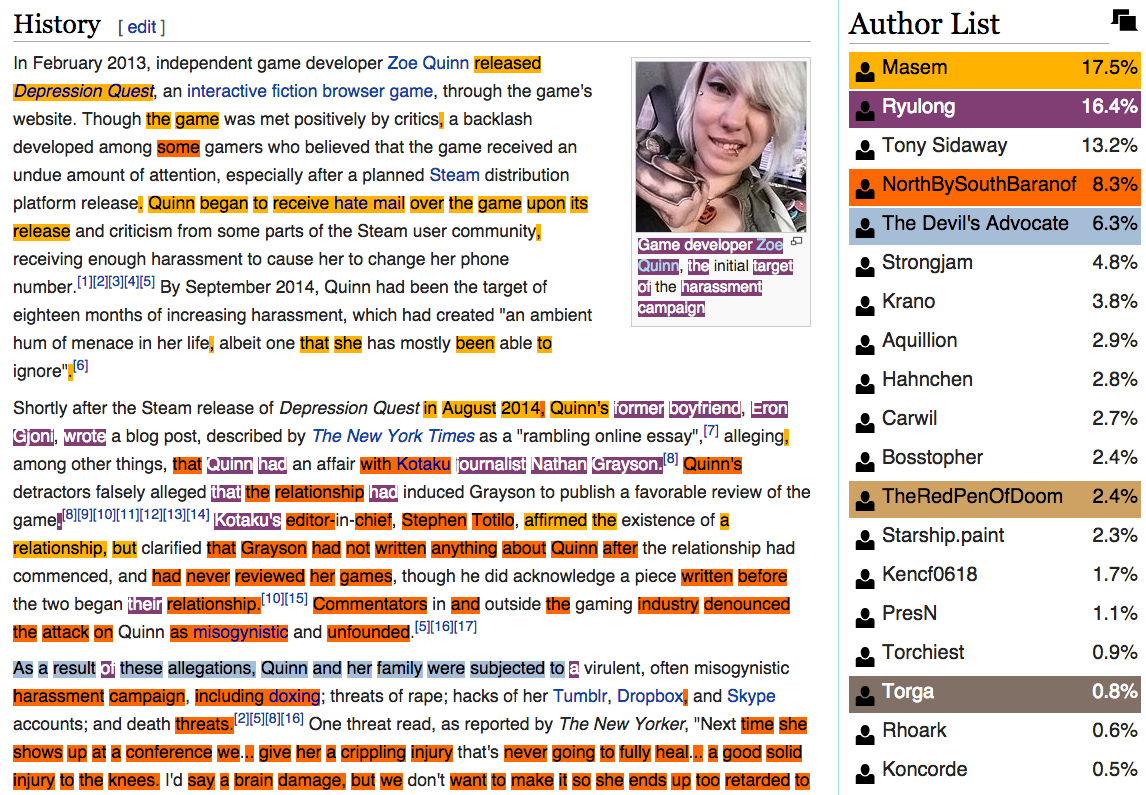
For WhoColor, we use an individual-token-level heuristic to compute conflict scores; yet, the sensible identification of conflict or disputes (as opposed to collaboration or non-interaction) related to a specific part of a changing document over time still poses several open research questions – answers to which the WikiWho data can offer.
Another, related use case is the extraction of relations between editors in an article based on the minute interactions on each other’s content. We provided a first, relatively simple implementation of this in an extension of WikiWho, using "(re)delete" and "reintroduce" actions between editors to encode antagonistic and supporting actions. See the code on GitHub. We have also developed an interactive Web visualization (“WhoVIS”) that takes the antagonistic edit actions extracted in this manner (and weighted by speed, number of tokens changed, etc.) to draw an interaction network between editors in an article over time. In this manner, the relations between editors can be intuitively explored. A usable Web demo and a publication describing the approach are available.
Yet, the WikiWho data can be leveraged for much more intricate modeling of interactions, taking for instance into account the semantic content of changes, prior interactions of editors, etc.

We are also working on providing insights about editors of Wikipedia, based on WikiWho data: What they are working on, how successful they are in adding, deleting and replacing content, etc. A pilot project in this vein is a set of interactive, "clickable" Jupyter Notebooks called IWAAN that allow interactive analysis of article dynamics and editor behavior and that can be launched directly in the cloud here. (Source code available on GitHub)